This paper presents results of recordings made on the clicks of several Southern Bantu languages, Xhosa, Zulu, Ndebele, Swati, Southern Sotho, using various techniques. This study has several goals. The first is to extend and refine the present knowledge of acoustic and articulatory aspects of clicks production in these languages. The second is to show what are the common cues and what is different when clicks of these languages are compared. The third is to compare the biomechanical parameters accounting for the acoustic output of the click production mechanisms.
Aerodynamic parameters (oral and nasal airflow -Oaf & Naf-) were obtained using an Aeromask, Vaissière et al. (2010), Elmerich (2014). These parameters were recorded in synchronization with the acoustic signal. To understand the dynamics of articulatory processes optopalatographic data (OPG) were recorded, Birkholtz et al. (2023). These allow to visualize tongue movements every 10ms between the alveolar and velar areas of the vocal tract. Electroglottographic data (EGG) synchronized with the acoustic signal were obtained using a Laryngograph. Three Xhosa, three Zulu, one Ndebele, one Swati and one Southern Sotho speakers took part in the experiments.
Aerodynamic data show that the negative Oaf is a good marker to reveal the moment of the front closure release (Figure 1). This is true for all click in all languages and for all speakers. Naf measurements reveal some unexpected or still unseen facts. Indeed, in all languages negative Naf was observed slightly after the font click release. This was mainly observed with dental clicks but there also observation with the other clicks in Xhosa and Zulu. This negative Naf accounts fora short influx at the level of the velopharyngeal port shortly after the back closure release. This is likely possible because the tongue dorsum lowering and backing movements of the click is made with the velum still stick on the tongue dorsum and also because the velopharyneal port is open during the production.
OPG data reveal the timing of front and back closures and releases of clicks and the expansion of the suction cavity. Figure 2 displays an example of this for a dental click [|] in Ndebele.
EGG data recorded in Xhosa, Zulu and Ndebele, reveal some interesting features. Indeed, there is a similar pattern for all clicks (dental, alveolar and lateral) and for all speakers during the clicks phases. The EGG signal shows a slight initial lowering followed by a well-marked peak at the click release that is followed by a rapid lowering before another upward movement to the point where the vocal folds oscillate for the following vowel. We believe that these movements do not show opening and closing gestures of the glottis but they rather show oscillations (up and down movements) of the glottis following movements of the thyroid cartilage. Some exploratory video recordings made during the production of clicks in a perpendicular plane to the jaw confirm a systematic up and down movement of the thyroid cartilage during the production clicks.
The Aeromask, OPG, and EGG data obtained in the production of clicks Xhosa, Zulu, Ndebele, Swati, Southern Sotho allow refining the understanding of their production mechanisms by giving a better understanding of their timing and gestural coordination in relation to the acoustic output.
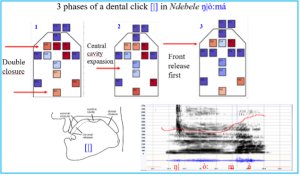
Figure 1. OPG frames, wideband spectrogram and F0 curve produced at three moments of the articulation of the dental click [|] in the Ndebele word ŋ|ò:má. Data recorded with the OPG systems (Birkholtz et al. 2023), spectrogram and F0 with winpitchpro.
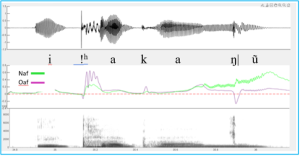
Figure 2. Audio waveform oral airflow (purple) nasal airflow (green) and wideband spectrogram of the word i!hakaŋ|ũ in Xhosa. Data recorded with an Aeromask (Vaissière et al. 2010). The red arrow marks the negative oral airflow at the release of the front closure of the dental click [|].
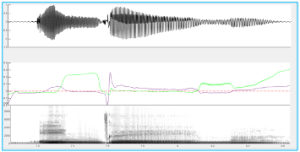
Figure 3. Audio waveform oral airflow (purple) nasal airflow (green) and wideband spectrogram of the word iŋ|ema in Swati. Data recorded with an Aeromask (Vaissière et al. 2010). The oblique red arrow marks the negative nasal airflow at the release of the front closure of the dental click [|]. The vertical arrows show the acoustic output of the front (plain arrow) and back releases (dotted arrow).

Figure 4. Audio waveform oral airflow (purple) nasal airflow (green) and wideband spectrogram of the word ŋith!ala| in Zulu. Data recorded with a Laryngograph. The red arrow marks the EGG pattern (green) found in clicks that still has not a satisfying explanation.